Graduated Non-Convexity (3)
지난 (2)편에서는 Black–Rangarajan Duality를 정리했다. 핵심은, robust estimation 문제
\[\min_{\mathbf{x}} \sum_{i=1}^N \rho(r_i(\mathbf{x})) \tag{2}\]를 각 measurement에 weight $w_i$를 도입해
\[\min_{\mathbf{x},\, w_i \in [0,1]} \sum_{i=1}^N \Big( w_i r_i^2(\mathbf{x}) + \Phi_\rho(w_i) \Big) \tag{3}\]꼴로 등가 변환할 수 있다는 것이었다. 그리고 Geman–McClure(GM) kernel의 경우, outlier process $\Phi_{\rho_\mu}(w) = \mu\bar{c}^2(\sqrt{w}-1)^2$이고, 최적 weight는
\[w^\star = \left( \frac{\mu\bar{c}^2}{r^2 + \mu\bar{c}^2} \right)^2\]라는 closed form으로 나온다는 것도 확인했다.
이번 글에서는 이 duality를 기반으로 GNC가 실제로 어떤 알고리즘을 구성하는지 정리한다.
전체 전략: 왜 $\mu$를 조정하는가?
GNC를 이해하는 가장 쉬운 방법은, GM surrogate의 모양이 $\mu$에 따라 어떻게 바뀌는지 먼저 보는 것이다. GM surrogate는
\[\rho_\mu(r) = \frac{\mu\bar{c}^2 r^2}{\mu\bar{c}^2 + r^2}\]로 주어지고, $\mu$가 클수록 $\rho_\mu(r)$는 $r^2$에 가까운 quadratic 형태를 보인다. 반대로 $\mu$를 줄이면 cost가 더 빨리 saturate하면서 큰 residual의 영향이 눌린다.
- $\mu \gg 1$: surrogate가 거의 $L_2$처럼 동작 → 매끈하고 풀기 쉬움
- $\mu \downarrow 1$: cost가 점점 robust해짐 → 큰 residual의 영향이 점차 줄어듦
- $\mu = 1$: 원래 GM cost를 회복
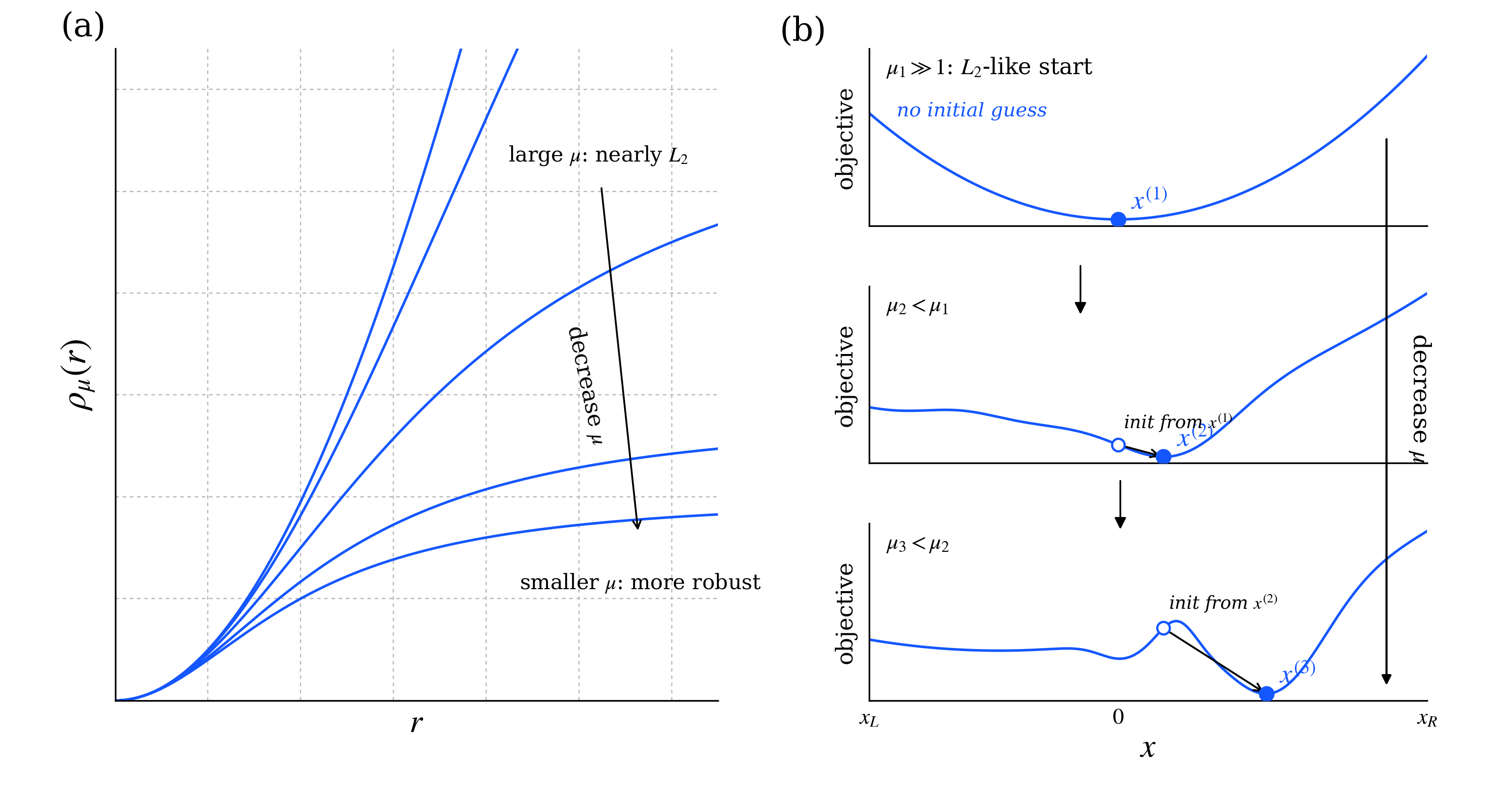
그림 1. (a) GM surrogate는 큰 $\mu$에서는 거의 $L_2$와 비슷하고, $\mu$를 줄일수록 더 robust한 형태로 바뀐다. (b) 초기값을 모를 때는 큰 $\mu$에서 얻은 해를 다음 단계의 초기값으로 넘기면서, 같은 $x$축 위에서 해를 조금씩 이동시켜 더 robust한 해를 추정한다.
그림 (a)는 바로 이 surrogate family를 보여준다. 큰 $\mu$에서는 곡선이 거의 quadratic이므로 최적화 landscape가 단순하다. 반면 $\mu$를 줄이면 cost가 빨리 평평해져서 큰 residual에 대한 penalty가 강하게 증가하지 않는다. 즉, outlier가 objective를 지배하지 못하도록 점차 막아주는 방향으로 문제가 바뀐다.
이제 중요한 질문은 다음이다. 초기값을 전혀 모를 때, 왜 굳이 $\mu$를 조정해야 할까?
처음부터 non-convex한 robust cost를 직접 최적화하면 local minimum에 갇히기 쉽다. 특히 초기값이 없으면 어느 basin으로 들어갈지 제어하기 어렵다. GNC는 이 문제를 정면으로 피하지 않고, 쉬운 문제에서 시작해 점점 어려운 문제로 들어가는 continuation 전략으로 다룬다.
구체적으로는, 먼저 큰 $\mu$에서 시작해 거의 $L_2$인 문제를 푼다. 이 단계에서는 landscape가 단순하므로 초기값이 없어도 안정적인 첫 해를 얻기 쉽다. 그리고 $\mu$를 조금 줄여 surrogate를 더 robust하게 만든 뒤, 바로 직전 단계에서 구한 해를 다음 $\mu$에서의 초기값으로 사용한다. 그러면 objective가 한 번에 크게 바뀌지 않기 때문에 해가 같은 $x$축 위에서 조금씩 이동하면서, 처음에는 outlier까지 같이 설명하던 $L_2$ 해에서 출발해 점차 inlier를 더 잘 설명하는 방향으로 보정된다.
이 관점에서 보면 GNC는 “처음부터 outlier를 강하게 잘라내는 방법”이라기보다, 좋은 초기값을 스스로 만들어 가면서 outlier의 영향을 서서히 약화시키는 방법에 가깝다. 큰 $\mu$에서는 대부분의 measurement가 비슷하게 반영되지만, $\mu$가 작아질수록 큰 residual의 영향이 점차 줄어들고, 그 결과 이전 단계의 해를 warm start로 써서 더 robust한 해로 넘어갈 수 있다.
참고로 GM에서는 $\mu$를 증가시키는 것이 아니라, 큰 값에서 시작해 점차 줄이는 방식이 맞다. 따라서 “점점 robust해진다”는 말은 GM의 경우 “점점 더 작은 $\mu$를 사용한다”는 뜻이다.
GNC 알고리즘 구조
알고리즘은 outer iteration과 inner iteration 두 층으로 구성된다.
Outer iteration: $\mu$를 고정하고, 현재 surrogate에 대한 최적해를 구한다. Inner iteration: 주어진 $\mu$에서 alternating optimization으로 $\mathbf{x}$와 $\mathbf{w}$를 번갈아 업데이트한다.
Outer loop: surrogate 최적화
각 outer iteration에서, 고정된 $\mu$에 대해
\[\min_{\mathbf{x}} \sum_{i=1}^N \rho_\mu(r_i(\mathbf{y}_i, \mathbf{x})) \tag{7}\]를 푼다. 이걸 직접 풀지 않고, Black–Rangarajan duality를 써서
\[\min_{\mathbf{x},\, w_i \in [0,1]} \sum_{i=1}^N \Big[ w_i r_i^2(\mathbf{y}_i, \mathbf{x}) + \Phi_{\rho_\mu}(w_i) \Big] \tag{8}\]로 바꾼 뒤 alternating optimization으로 푼다.
Inner loop: alternating optimization
식 (8)은 $\mathbf{x}$와 $\mathbf{w} = (w_1, \ldots, w_N)$ 두 변수에 대한 문제인데, 두 변수를 동시에 최적화하기 어려우니 번갈아 풀면 된다.
Step 1 — Variable update ($w_i$ 고정, $\mathbf{x}$ 업데이트):
\[\mathbf{x}^{(t)} = \arg\min_{\mathbf{x} \in \mathcal{X}} \sum_{i=1}^N w_i^{(t-1)} r_i^2(\mathbf{y}_i, \mathbf{x}). \tag{9}\]이건 $w_i$를 상수로 보면 그냥 weighted least squares 문제다. $w_i$ 항들은 $\mathbf{x}$와 무관하므로 식 (8)에서 $\Phi_{\rho_\mu}(w_i)$ 항은 사라진다. 즉, 기존에 outlier가 없다고 가정하고 만들어진 solver (non-minimal solver)를 weight만 바꿔서 그대로 재활용할 수 있다.
Step 2 — Weight update ($\mathbf{x}$ 고정, $w_i$ 업데이트):
\[\mathbf{w}^{(t)} = \arg\min_{w_i \in [0,1]} \sum_{i=1}^N \Big[ w_i r_i^2(\mathbf{y}_i, \mathbf{x}^{(t)}) + \Phi_{\rho_\mu}(w_i) \Big]. \tag{10}\]$\mathbf{x}^{(t)}$이 고정되면 $r_i^2$도 상수가 되므로, 이 문제는 $w_i$들에 대한 독립적인 1차원 scalar 문제 $N$개로 쪼개진다. 각 $w_i$를 따로따로 최소화하면 된다. GM의 경우 이게 closed form으로 떨어진다는 것을 지난 글에서 확인했다.
GNC-GM: 구체적 알고리즘
이제 위 구조를 GM에 적용한다.
Proposition (GNC-GM)
GM surrogate $\rho_\mu$에 대응하는 outlier process는
\[\Phi_{\rho_\mu}(w_i) = \mu\bar{c}^2(\sqrt{w_i} - 1)^2. \tag{11}\]이때 weight update의 closed form 해는
\[w_i^{(t)} = \left( \frac{\mu\bar{c}^2}{\tilde{r}_i^2 + \mu\bar{c}^2} \right)^2, \tag{12}\]여기서 $\tilde{r}_i^2 = r_i^2(\mathbf{y}_i, \mathbf{x}^{(t)})$이다.
이미 지난 글에서 직접 유도한 내용이다. 요약하면: $f(w) = wr^2 + \mu\bar{c}^2(\sqrt{w}-1)^2$을 $u = \sqrt{w}$로 치환해 미분하면 $u^\star = \mu\bar{c}^2/(r^2+\mu\bar{c}^2)$이 나오고, $w^\star = (u^\star)^2$이다.
$\mu$ 스케줄링
GNC-GM에서 $\mu$는 큰 값에서 시작해 1보다 작아질 때까지 줄여간다.
- 초기화: 첫 번째 variable update 후 얻은 최대 residual $r_{\max}^2 = \max_i r_i^2(\mathbf{y}_i, \mathbf{x}^{(0)})$를 이용해
로 설정한다. 이렇게 하면 처음 $\mu$에서 surrogate가 충분히 convex하게 시작된다.
- 감소 방식: 매 outer iteration마다
로 줄인다.
종료 조건: $\mu < 1$이 되면 원래 GM cost에 충분히 가까워졌다고 보고 종료한다.
가중치 초기화: 알고리즘 시작 시 모든 weight를 $w_i^{(0)} = 1$로 초기화한다. 즉 처음에는 모든 measurement를 동등하게 신뢰하는 것에서 출발한다.
전체 알고리즘 흐름 정리
GNC-GM의 전체 흐름을 정리하면 다음과 같다.
초기화:
\[w_i^{(0)} = 1 \quad \forall i, \qquad \mathbf{x}^{(0)} = \arg\min_{\mathbf{x}} \sum_i r_i^2(\mathbf{y}_i, \mathbf{x}), \qquad \mu = \frac{2r_{\max}^2}{\bar{c}^2}.\]첫 번째 $\mathbf{x}^{(0)}$은 weight 없이 (즉 uniform weight로) non-minimal solver를 한 번 돌린 것이다.
반복 (outer iteration):
while $\mu \geq 1$:
- Weight update: 현재 $\mathbf{x}^{(t)}$와 $\mu$로 각 measurement의 weight를 갱신한다.
- Variable update: 갱신된 weight $\mathbf{w}^{(t)}$로 weighted least squares를 풀어 $\mathbf{x}$를 갱신한다.
- $\mu$ 감소: $\mu \leftarrow \mu / 1.4$.
왜 이 방법이 local optimum을 피하는가?
전통적인 M-estimation은 식 (2)를 초기값에서 시작해 gradient descent로 푼다. 초기값이 좋지 않으면 non-convexity 때문에 local optimum에 빠진다.
GNC는 다르다. 처음에는 $\mu$가 크기 때문에 surrogate $\rho_\mu$가 거의 convex하다. 이 상태에서 non-minimal solver를 쓰면 초기값 없이 global optimum을 찾을 수 있다. 이후 $\mu$를 줄여가면서 점차 non-convex한 원래 문제로 접근하는데, 각 단계에서 이전 해를 starting point로 쓰기 때문에 landscape가 조금씩만 바뀌는 동안 해가 자연스럽게 따라간다.
비유하자면, 울퉁불퉁한 산맥 지형을 안개가 점차 걷히면서 보이기 시작하는 상황과 비슷하다. 처음에는 부드러운 언덕만 보이니까 쉽게 최저점을 찾는다. 점점 안개가 걷히며 진짜 복잡한 지형이 드러나지만, 우리는 이미 “진짜 최저점 근처”에 있기 때문에 엉뚱한 골짜기에 빠지지 않는다.
GM weight의 직관적 해석
매 iteration에서 GM weight
\[w_i = \left( \frac{\mu\bar{c}^2}{\tilde{r}_i^2 + \mu\bar{c}^2} \right)^2\]는 현재 $\mathbf{x}^{(t)}$ 기준으로 “이 measurement가 inlier일 가능성”을 나타낸다.
- $\tilde{r}_i^2 \ll \mu\bar{c}^2$이면: $w_i \approx 1$ → 이 measurement는 inlier, 거의 full weight를 받는다.
- $\tilde{r}_i^2 \gg \mu\bar{c}^2$이면: $w_i \approx 0$ → 이 measurement는 outlier, 거의 무시된다.
흥미로운 점은 $\mu$의 역할이다. $\mu$가 클 때는 분모의 $\mu\bar{c}^2$ 항이 크기 때문에 $\tilde{r}_i^2$이 상당히 커도 $w_i$가 아직 1에 가깝다. 즉 초반에는 웬만한 outlier도 inlier처럼 취급한다. $\mu$가 줄어들수록 기준이 점점 엄격해져서, 최종적으로 $\mu = 1$에서는 원래 GM kernel의 기준으로 outlier를 걸러낸다.
이것이 GNC가 “졸업”(graduated)이라는 이름을 가진 이유다. outlier를 처음부터 적극적으로 제거하는 대신, 점차적으로 기준을 높여가며 천천히 걸러낸다.
마무리
GNC 알고리즘의 핵심을 다시 정리하면 다음과 같다.
① $\mu$ 조절로 non-convexity를 점진적으로 도입한다.
\[\mu\text{가 크면} \Rightarrow \rho_\mu \approx r^2 \text{ (convex)}, \qquad \mu = 1 \Rightarrow \rho_\mu = \rho \text{ (원래 robust cost)}.\]② Black–Rangarajan duality로 각 outer iteration을 alternating optimization 두 단계로 분해한다.
\[\text{Variable update:} \quad \mathbf{x}^{(t)} = \arg\min_\mathbf{x} \sum_i w_i^{(t-1)} r_i^2 \quad \text{(weighted least squares)}\] \[\text{Weight update:} \quad w_i^{(t)} = \left( \frac{\mu\bar{c}^2}{\tilde{r}_i^2 + \mu\bar{c}^2} \right)^2 \quad \text{(closed form)}\]③ Variable update는 기존 non-minimal solver를 그대로 쓸 수 있다.
이것이 이 논문의 가장 실용적인 기여라고 생각한다. robust cost를 직접 최적화하는 새로운 solver를 만드는 게 아니라, outlier-free 문제를 위해 이미 존재하는 globally optimal non-minimal solver를 재활용한다는 발상이다. 덕분에 point cloud registration, pose graph optimization 등 다양한 spatial perception 문제에 곧바로 적용할 수 있다.
다음 포스트에서는 이 아이디어가 실제로 어떻게 쓰이는지 보기 위해, Point Set Registration과 Pose Graph Optimization을 예시로 살펴보려고 한다.